网上查了查资料,这里记录一下。
前言
最近分析服务器性能,考虑到nginx在前面做反向代理,这里查一下nginx日志来反应服务器处理时间的问题。
注:本文提到的所有变量,如果需要区分,则均为ngx_http_upstream_module中的变量,不再做释义。如需要使用其他module中的参数,请参考nginx官方文档
网上查了查资料,这里记录一下。
前言
最近分析服务器性能,考虑到nginx在前面做反向代理,这里查一下nginx日志来反应服务器处理时间的问题。
注:本文提到的所有变量,如果需要区分,则均为ngx_http_upstream_module中的变量,不再做释义。如需要使用其他module中的参数,请参考nginx官方文档
最近工作中遇到一个问题,某个请求的响应特别慢,因此我就希望有一种方法能够分析到底请求的哪一步耗时比较长,好进一步找到问题的原因。在网络上搜索了一下,发现了一个非常好用的方法,curl 命令就能帮你分析请求的各个部分耗时。
We have already gone through some limitations of DHCP Fail-over in windows server 2012, if you have missed my previous article here is the link
https://sjohnonline.blogspot.com/2018/12/dhcp-fail-over-implementation-windows.html
Microsoft provided a solution to overcome some of the limitation, which is a PowerShell script which is detailed below in this article.
Anyway this limitations are not there in the windows server 2016 release
DHCP Failover on windows Server 2012 is a good alternative for DHCP in a Windows failover cluster and Split scope DHCP. But If the user makes any changes in any property/configuration (e.g. add/remove option values, reservation) of a failover scope, he/she needs to ensure that it is replicated to the failover server.
Windows Server 2012 provides functionality for performing this replication using DHCP MMC as well as PowerShell. But these require initiation by the user.
This requirement for explicitly initiating replication of scope configuration can be avoided by using a tool which automates this task of replicating configuration changes on the failover server. DHCP Failover Auto Config Sync (DFACS) is a PowerShell based tool which automates the synchronization of configuration changes. This document is a guide to using DFACS.
官方镜像下载地址:http://cloud.centos.org/centos/
OpenStack环境中,使用官方镜像CentOS-7-x86_64-GenericCloud.qcow2,我们不知道镜像的默认密码,可以在创建实例时候配置脚本写入root密码。
操作方法
在创建实例——定制化脚本的输入框中输入以下内容
#!/bin/bash
passwd root<<EOF
1234qwer
1234qwer
EOF
sed -i 's/PasswordAuthentication no/PasswordAuthentication yes/g' /etc/ssh/sshd_config
systemctl restart sshd
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
setenforce 0
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
DR(Direct Routing)
所谓丢包,是指在网络数据的收发过程中,由于种种原因,数据包还没传输到应用程序中,就被丢弃了。这些被丢弃包的数量,除以总的传输包数,也就是我们常说的丢包率。丢包率是网络性能中最核心的指标之一。丢包通常会带来严重的性能下降,特别是对 TCP 来说,丢包通常意味着网络拥塞和重传,进而还会导致网络延迟增大、吞吐降低。
docker volume 可以使我们在启动docker容器时,动态的挂载一些文件(如配置文件), 以覆盖镜像中原有的文件,但是,挂载一个主机上尚不存在的文件夹或者文件到容器中会怎样呢?LZ在工作中就遇到了这样的问题,故自己实践了一下,记录实验结果如下:
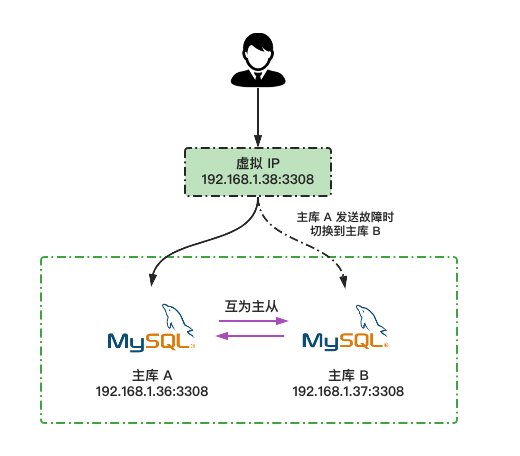
在传统的主从复制架构中,从库仅仅是作为主库数据的备份,当主库发生故障时,数据库将停止对外提供服务,并且主库故障后手动进行主从切换的过程也较为繁琐。为了解决这个问题,可以采用 MySQL 双主模式,其中一台主库提供服务,另一台作为热备。结合 keepalived 使用虚拟 IP 对外提供服务,一旦主库发生故障,备库可以在很短的时间内接管服务。
Zabbix 是一个企业级分布式开源监控解决方案,能够监控各种网络设备、服务器、中间件和应用程序等等。Zabbix 支持主动轮询(polling)和被动捕获(trapping)两种方式获取数据。Zabbix 所有的报表、统计数据和配置参数都可以通过基于 Web 的前端页面进行访问,并且提供了完善的 API 接口便于二次开发。
Zabbix 有以下几个主要组件:
目前 Zabbix 最新的稳定版本是 5.4,然而官方 yum 源只支持在 Centos8 上安装 Zabbix 5.4 版本,想要在 Centos7 上安装 Zabbix 5.4 版本上只能通过源码编译的方式安装。本文将会介绍在 Centos7 上通过源码编译安装的方式部署一套 Zabbix 高可用集群。
根据最佳实践做法,Management、vMotion、vSphereFT、iSCSI等的网络相互隔离,从而提高安全性和性能。同时每个网络建议配置2块物理网卡用作冗余和负载均衡,根据最佳实践可能至少需要6块网卡,多则十几块网卡,这对标配4块网卡的机架式服务器是不现实的。